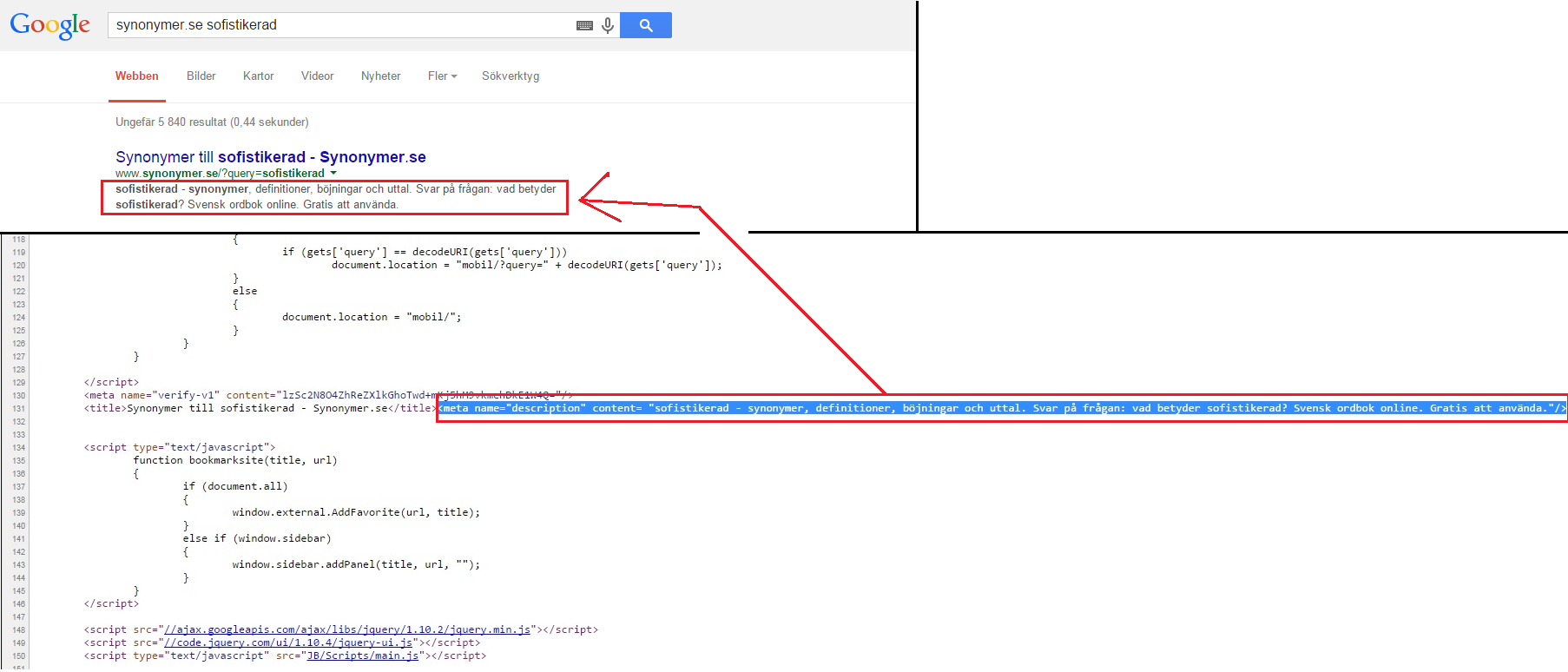
I denna del av inlägget kommer jag att hänvisa till en mycket användbar och bra webb-referenssida hos learn.shayhowe.com som i detalj går igenom viktiga saker värda att ha koll på för HTML(5) semantik.
När vi pratar blockelement och en webbsidas struktur så kom HTML5’s kod-standard med en del nya tillskott som ni redan fått se som hastigast i tidigare inlägg, men som kanske inte diskuterats i detalj med fokus på deras semantiska sida.
Varför nya element med HTML5?
Utvecklarna av den nya HTML5 standarden gjorde som sagt undersökningar för att ta reda på vilka som var de vanligaste klasserna och ID som användes för strukturella element som t ex. <div> på webbsidor över hela internet. Detta ledde till att man hittade ett antal klasser och ID som återkom oftare än andra, och man beslutade därför att förenkla genom att skapa nya element för dessa typer av blockelement så att man slipper ständigt ange samma klasser och ID för massa olika webbsidor.
Då skapades:
<header></header>som ersättare till<div id="header"></div>t ex. för sidhuvud<footer></footer>som ersättare till<div id="footer"></div>för sidfot<aside></aside>som ersättare till<div id="aside"></div>(sidebar/sidospalt)<article></article>som ersättare till<div id="article"></div><section></section>som ersättare till<div></div>eller<div id="section"></div>eller<div class="section"></div>(sektionsavdelare)<nav></nav>som ersättare till<div id="nav"></div>(navigations område)
De nya elementen (tycker jag iaf.) är betydligt mer utvecklar-vänliga och sparar en hel del tid, såväl som förser webbdokument i allmänhet med en bättre arsenal av strukturella element. De förmedlar också på ett bättre sätt för både utvecklare, såväl som indexeringsrobotar vad elementet är till för på webbsidan (indexeringsrobotarna kunde inte läsa och förstå ID och klass attribut, däremot kan de läsa och ”förstå” taggnamn).
Därför säger jag att vi får nu ta vara på att vi äntligen fått bättre semantiskt bestyckade element att märka upp våra webbsidor med, dissa <div> taggar och extra- nu överflödiga: ID och klasser, som inte längre behövs nu när vi har våra nya element ;)
Översikt av de nya HTML5-elementen
HTML5Doctor är en bra referenssida om ni vill ha en översikt av de nya taggarna och ni kan även besöka deras HTML5-Element Index för uppsökande av specifika, eller generell översikt av samtliga nya taggar – de står listade i bokstavsordning.
Uppgradera er utdaterade element-arsenal med nya fräscha semantiska HTML5-element!
Läs gärna på lite på HTML5-Element indexet som HTML5Doctor erbjuder och fyll på ert HTML-taggs förråd med de senaste nya taggarna och börja använda de så ofta ni får möjligheten för bättre semantisk och sökmotoroptimerings anpassad HTML5-kodning.
Det finns alldeles för många nya tillskott för att hinna gå igenom i detta inlägg, dock kommer jag som jag nämnde ovan hänvisa till några väldigt användbara punkter som jag själv haft stor användning för som learn.shayhowe.com HTML5-semantics hjälpte till att förtydliga för mig.
Tips: Då HTML5 fortfarande är relativt nytt och saknar stöd i vissa webbläsare, kolla vad som funkar vart
Och nu för att gå vidare och kolla på textspecifika semantiska inline-element som kan vara användbart att känna till:
Förklaring och uppvisning av semantiska skillnader i HTML5-element
Två alternativ för att få fetstil på sin webbsidas text, med olika semantiska betydelser!
De två HTML(5)-element vi har att jobba med är <strong> & <b>. Dock skiljer dessa sig åt ganska mycket i mån av semantisk betydelse.
<strong> används för att markera ”Stark viktighet” / ”Strong Importance” på engelska. Medan <b> istället används för att avse en ”stilistisk fetstil” utan direkt innebörd.
Nedan kan ni se citat från hur learn.shayhowe.com förklarar detta i kod:
<!-- Strong importance --> <strong>Caution:</strong> Falling rocks. <!-- Stylistically offset --> This recipe calls for <b>bacon</b> and <b>baconnaise</b>.
Två sätt för att få kursiverad text på sin webbsida, med olika semantiska betydelser!
De två HTML(5)-element vi har att jobba med för detta är istället <em> & <i>. Dessa skiljer sig på liknande sätt som ovan två valsalternativ för fetstils text-märkning.
<em> används för att markera något av ”stressad vikt/betydelse” / ”Stressed Importance” på engelska. Medan <i> hellre avser att markera en annorlunda/alternativ ”röst/ton” och används mer i dialog-sammanhang & talspråk för innehåll.
Nedan kan ni se citat från hur learn.shayhowe.com förklarade detta i kod:
<!-- Stressed emphasis --> I <em>love</em> Chicago! <!-- Alternative voice or tone --> The name <i>Shay</i> means a gift.
För att läsa på mer om olika semantiska skillnader mellan liknande funktionella HTML(5)-taggar så kolla gärna vidare på learn.shayhowe.com’s genomgång av HTML5-semantik då den artikeln även går igenom saker som: Understrykning av text, Genomstrykning av text, Upplysning/Highlightning av text, Förkortnings markering i text, Upphöjning (superscript) av text och Nedsänkning (subscript) av text – t ex. nedsänkning vid representation av H2O hade blivit: H2O, medan en upphöjning istället t ex. vid användning av kvadratmeter (m2) hade kunnat se ut som: m2. Sedan går artikeln även igenom saker som: Framstegsmätare (progress-meter), semantisk uppmärkning av tid & datum, hur man presenterar kod på webben, såväl som linje- och ord-brytningar (<wbr> & <br>), Citering, m.m.
Genomgång av Semantisk märkning av textinnehåll med <h1>-rubriker och <p>-paragrafer för textstycken:
När man skriver texter så är ovan visade genomgångar av kursivering och fetstil väldigt användbara och viktiga, men det är även simplare och mer direkt semantisk uppmärkning som Rubriker (via <h1>, <h2>, <h3>, osv.), såväl som paragrafer/textstycken (<p>), sektions-avdelare/skiljestreck (<hr />) för att distinkt markera brytstället där en del av sidan övergår till en helt annan del av sidan, m.fl. andra.
Dock så tänkte jag bara snabbt gå igenom vikten av Rubriktexter och deras innehåll då även detta är en Väldigt viktig del inom On-page sökmotoroptimering!
Den ”första” rubriktexten tillgänglig är <h1> och är då den som är av störst vikt och sedan dalar viktigheten för resterande rubriktexter tillgängliga för varje steg man går – notera dock! att <h2> t ex. är en typ av underrubrik till <h1> och bör användas som sådan!
Ett praktiskt exempel – skulle ni ha en <h1> rubrik för er logotype om ni valt att köra den ”textbaserad” som jag själv brukar göra då detta är lättare att sökmotoroptimera jämfört med en bild som praktiskt taget inte går att indexera för sökmotor-bottarna så skulle <h2>-taggarna kunna användas för sid-innehållets första rubriker då de är underrubriker till sidan – men detta är lite av en tolkningsfråga och är helt upp till er hur ni väljer att tolka sidans struktur – tänk bara på att den struktur ni väljer att köra sidan utefter – är även den struktur indexeringsrobotarna kommer att uppfatta!
Men jag skulle nog annars vilja påstå att <h1>-taggen och dessa rubriktexts-elementen kommer någonstans efter <title>-taggen i vikt när det gäller On-page sökmotoroptimering!